- Published on
Advanced Prompt Caching Patterns: Mastering Claude's Memory for Production Applications
- Authors

- Name
- Anablock
AI Insights & Innovations
Advanced Prompt Caching Patterns: Mastering Claude's Memory for Production Applications
Take your prompt caching implementation to the next level with advanced strategies, edge case handling, and production-ready patterns.
If you've already implemented basic prompt caching in your Claude applications, you're seeing the benefits: faster responses and lower costs. But there's a whole world of advanced patterns that can squeeze even more performance and savings from this feature.
This guide explores sophisticated caching strategies used by high-volume production applications, complete with code examples and real-world scenarios.
Table of Contents
- Multi-Level Cache Hierarchies
- Dynamic Cache Invalidation Strategies
- Cache Warming and Preloading
- Conversation State Management
- Hybrid Caching with External Stores
- Cost Optimization Algorithms
- Cache Analytics and Monitoring
- Edge Cases and Failure Modes
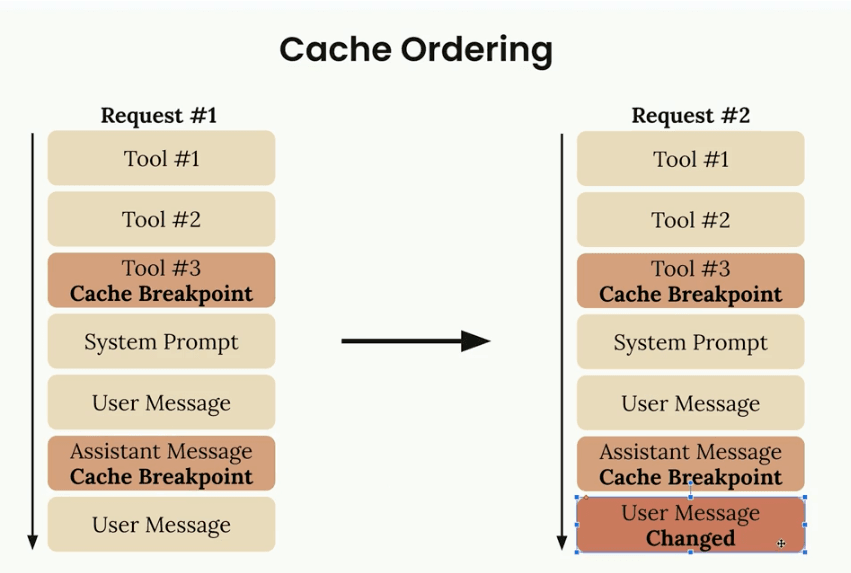
Multi-Level Cache Hierarchies
Instead of caching everything at once, sophisticated applications use multiple cache breakpoints to create a hierarchy of cached content with different invalidation frequencies.
The Pattern
interface CacheLayer {
name: string;
content: string;
tokens: number;
changeFrequency: 'never' | 'hourly' | 'daily' | 'per-request';
}
class HierarchicalCacheManager {
private layers: CacheLayer[] = [];
addLayer(layer: CacheLayer): void {
this.layers.push(layer);
}
buildCachedContent(): Anthropic.ContentBlock[] {
const content: Anthropic.ContentBlock[] = [];
// Sort by change frequency (most stable first)
const sortedLayers = [...this.layers].sort((a, b) => {
const order = { 'never': 0, 'daily': 1, 'hourly': 2, 'per-request': 3 };
return order[a.changeFrequency] - order[b.changeFrequency];
});
// Add cache breakpoints at layer boundaries
for (let i = 0; i < sortedLayers.length; i++) {
const layer = sortedLayers[i];
const isLastStableLayer = i < sortedLayers.length - 1 &&
sortedLayers[i + 1].changeFrequency === 'per-request';
content.push({
type: 'text',
text: layer.content,
...(layer.changeFrequency !== 'per-request' && {
cache_control: { type: 'ephemeral' }
})
});
}
return content;
}
}
// Usage example
const cacheManager = new HierarchicalCacheManager();
// Layer 1: Static tool definitions (never change)
cacheManager.addLayer({
name: 'tools',
content: JSON.stringify(TOOL_DEFINITIONS),
tokens: 1700,
changeFrequency: 'never'
});
// Layer 2: System prompt (changes daily)
cacheManager.addLayer({
name: 'system',
content: getSystemPromptForDate(new Date()),
tokens: 2000,
changeFrequency: 'daily'
});
// Layer 3: User context (changes hourly)
cacheManager.addLayer({
name: 'context',
content: getUserContext(userId),
tokens: 5000,
changeFrequency: 'hourly'
});
// Layer 4: Current query (changes every request)
cacheManager.addLayer({
name: 'query',
content: userQuestion,
tokens: 100,
changeFrequency: 'per-request'
});
const content = cacheManager.buildCachedContent();
Why This Works
When you update the hourly context, the daily system prompt and static tools remain cached. You only pay for reprocessing the changed layer and everything after it.
Cost breakdown:
- Without hierarchy: Reprocess all 8,800 tokens
- With hierarchy: Reprocess only 5,100 tokens (context + query)
- Savings: 42% on cache invalidation events
Dynamic Cache Invalidation Strategies
Smart applications don't just cache blindly—they track content versions and invalidate caches strategically.
Content Versioning Pattern
from typing import Dict, Optional
from hashlib import sha256
from datetime import datetime, timedelta
class CacheVersionManager:
"""Track content versions to detect when cache invalidation is needed."""
def __init__(self):
self.versions: Dict[str, str] = {}
self.last_updated: Dict[str, datetime] = {}
def get_content_hash(self, content: str) -> str:
"""Generate a hash of content for version tracking."""
return sha256(content.encode()).hexdigest()[:16]
def should_invalidate(
self,
key: str,
content: str,
max_age_minutes: Optional[int] = None
) -> bool:
"""Determine if cache should be invalidated."""
current_hash = self.get_content_hash(content)
# Check if content changed
if key not in self.versions or self.versions[key] != current_hash:
self.versions[key] = current_hash
self.last_updated[key] = datetime.now()
return True
# Check if cache is too old
if max_age_minutes and key in self.last_updated:
age = datetime.now() - self.last_updated[key]
if age > timedelta(minutes=max_age_minutes):
return True
return False
def get_cache_strategy(
self,
system_prompt: str,
tools: list,
document: str
) -> Dict[str, bool]:
"""Determine which components need cache invalidation."""
return {
'system': self.should_invalidate('system', system_prompt, max_age_minutes=60),
'tools': self.should_invalidate('tools', str(tools)),
'document': self.should_invalidate('document', document, max_age_minutes=30)
}
# Usage
version_manager = CacheVersionManager()
def create_request_with_smart_caching(system, tools, document, question):
"""Build request with intelligent cache invalidation."""
strategy = version_manager.get_cache_strategy(system, tools, document)
# Only add cache control if content hasn't changed
system_block = [
{
"type": "text",
"text": system,
**({"cache_control": {"type": "ephemeral"}} if not strategy['system'] else {})
}
]
# Build tools with conditional caching
tools_with_cache = tools.copy()
if not strategy['tools'] and tools:
last_tool = tools_with_cache[-1].copy()
last_tool["cache_control"] = {"type": "ephemeral"}
tools_with_cache[-1] = last_tool
# Build content with conditional document caching
content = [
{
"type": "text",
"text": f"Document:\n\n{document}",
**({"cache_control": {"type": "ephemeral"}} if not strategy['document'] else {})
},
{
"type": "text",
"text": question
}
]
return {
"system": system_block,
"tools": tools_with_cache,
"messages": [{"role": "user", "content": content}]
}
Time-Based Invalidation
class TimeBasedCacheManager {
private cacheTimestamps: Map<string, number> = new Map();
shouldCache(
key: string,
ttlMinutes: number = 60
): boolean {
const now = Date.now();
const lastCached = this.cacheTimestamps.get(key);
if (!lastCached) {
this.cacheTimestamps.set(key, now);
return true;
}
const ageMinutes = (now - lastCached) / 1000 / 60;
if (ageMinutes >= ttlMinutes) {
this.cacheTimestamps.set(key, now);
return true;
}
return false;
}
buildSystemPrompt(basePrompt: string): Anthropic.SystemPrompt {
const shouldAddCache = this.shouldCache('system_prompt', 60);
return [
{
type: 'text',
text: basePrompt,
...(shouldAddCache && { cache_control: { type: 'ephemeral' } })
}
];
}
}
Cache Warming and Preloading
For predictable workloads, you can "warm" the cache before users make requests, ensuring the first request is already fast.
Preloading Pattern
import asyncio
from anthropic import AsyncAnthropic
class CacheWarmer:
"""Preload caches for predictable content."""
def __init__(self, api_key: str):
self.client = AsyncAnthropic(api_key=api_key)
self.warmed_caches = set()
async def warm_document_cache(
self,
document_id: str,
document_content: str,
system_prompt: str
):
"""Warm cache for a document before users request it."""
if document_id in self.warmed_caches:
return # Already warmed
# Make a minimal request to populate the cache
await self.client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=10, # Minimal output
system=[
{
"type": "text",
"text": system_prompt,
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": f"Document:\n\n{document_content}",
"cache_control": {"type": "ephemeral"}
},
{
"type": "text",
"text": "Ready" # Minimal query
}
]
}
]
)
self.warmed_caches.add(document_id)
print(f"✓ Cache warmed for document: {document_id}")
async def warm_multiple_documents(
self,
documents: list[tuple[str, str]],
system_prompt: str,
concurrency: int = 5
):
"""Warm caches for multiple documents concurrently."""
semaphore = asyncio.Semaphore(concurrency)
async def warm_with_limit(doc_id, doc_content):
async with semaphore:
await self.warm_document_cache(doc_id, doc_content, system_prompt)
tasks = [
warm_with_limit(doc_id, content)
for doc_id, content in documents
]
await asyncio.gather(*tasks)
# Usage
async def main():
warmer = CacheWarmer(api_key="your_key")
# Warm caches for today's most-accessed documents
popular_docs = [
("contract_123", load_document("contract_123.txt")),
("report_456", load_document("report_456.txt")),
("policy_789", load_document("policy_789.txt"))
]
system_prompt = "You are a document analysis expert..."
await warmer.warm_multiple_documents(popular_docs, system_prompt)
print("All caches warmed and ready!")
# Run as a scheduled job (e.g., every 50 minutes to keep cache alive)
asyncio.run(main())
Scheduled Cache Refresh
class ScheduledCacheRefresher {
private refreshIntervals: Map<string, NodeJS.Timeout> = new Map();
scheduleRefresh(
cacheKey: string,
refreshFn: () => Promise<void>,
intervalMinutes: number = 50 // Refresh before 60-minute expiry
): void {
// Clear existing interval if any
this.cancelRefresh(cacheKey);
// Initial refresh
refreshFn();
// Schedule periodic refresh
const interval = setInterval(
() => refreshFn(),
intervalMinutes * 60 * 1000
);
this.refreshIntervals.set(cacheKey, interval);
}
cancelRefresh(cacheKey: string): void {
const interval = this.refreshIntervals.get(cacheKey);
if (interval) {
clearInterval(interval);
this.refreshIntervals.delete(cacheKey);
}
}
cancelAll(): void {
for (const interval of this.refreshIntervals.values()) {
clearInterval(interval);
}
this.refreshIntervals.clear();
}
}
// Usage
const refresher = new ScheduledCacheRefresher();
refresher.scheduleRefresh(
'legal_documents',
async () => {
await warmCacheForLegalDocuments();
console.log('Legal document cache refreshed');
},
50 // Refresh every 50 minutes
);
Conversation State Management
For multi-turn conversations, managing what gets cached and when is critical for both performance and cost.
Sliding Window Cache Pattern
from typing import List, Dict
from collections import deque
class ConversationCacheManager:
"""Manage conversation history with sliding window caching."""
def __init__(
self,
max_cached_turns: int = 10,
cache_threshold_tokens: int = 5000
):
self.max_cached_turns = max_cached_turns
self.cache_threshold_tokens = cache_threshold_tokens
self.conversation_history = deque(maxlen=max_cached_turns * 2)
self.total_tokens = 0
def add_turn(self, user_msg: str, assistant_msg: str, tokens: int):
"""Add a conversation turn."""
self.conversation_history.append({
"user": user_msg,
"assistant": assistant_msg,
"tokens": tokens
})
self.total_tokens += tokens
def build_messages_with_cache(
self,
new_user_message: str
) -> List[Dict]:
"""Build messages array with strategic cache breakpoint."""
messages = []
# Add historical turns (cached if above threshold)
history_tokens = 0
for turn in self.conversation_history:
messages.append({
"role": "user",
"content": turn["user"]
})
messages.append({
"role": "assistant",
"content": turn["assistant"]
})
history_tokens += turn["tokens"]
# Add cache breakpoint after history if substantial
if history_tokens >= self.cache_threshold_tokens:
# Add a marker message with cache control
messages.append({
"role": "user",
"content": [
{
"type": "text",
"text": "[Conversation context above]",
"cache_control": {"type": "ephemeral"}
}
]
})
# Add new message (not cached)
messages.append({
"role": "user",
"content": new_user_message
})
return messages
def should_compress_history(self) -> bool:
"""Determine if history should be summarized."""
return len(self.conversation_history) >= self.max_cached_turns
# Usage
conversation = ConversationCacheManager(max_cached_turns=10)
# Simulate conversation
for i in range(15):
user_msg = f"Question {i}"
messages = conversation.build_messages_with_cache(user_msg)
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
messages=messages
)
assistant_msg = response.content[0].text
conversation.add_turn(user_msg, assistant_msg, response.usage.output_tokens)
# Compress history if needed
if conversation.should_compress_history():
# Summarize old turns and reset
summary = summarize_conversation(conversation.conversation_history)
conversation = ConversationCacheManager()
conversation.add_turn("Previous context", summary, 500)
Conversation Checkpointing
interface ConversationCheckpoint {
id: string;
timestamp: number;
messages: Anthropic.MessageParam[];
cacheState: {
systemHash: string;
toolsHash: string;
historyTokens: number;
};
}
class ConversationCheckpointer {
private checkpoints: Map<string, ConversationCheckpoint> = new Map();
createCheckpoint(
conversationId: string,
messages: Anthropic.MessageParam[],
cacheState: ConversationCheckpoint['cacheState']
): void {
this.checkpoints.set(conversationId, {
id: conversationId,
timestamp: Date.now(),
messages: JSON.parse(JSON.stringify(messages)), // Deep clone
cacheState
});
}
restoreCheckpoint(conversationId: string): ConversationCheckpoint | null {
const checkpoint = this.checkpoints.get(conversationId);
if (!checkpoint) return null;
// Check if checkpoint is still valid (within cache lifetime)
const ageMinutes = (Date.now() - checkpoint.timestamp) / 1000 / 60;
if (ageMinutes > 55) { // 5-minute buffer before 60-minute expiry
this.checkpoints.delete(conversationId);
return null;
}
return checkpoint;
}
async resumeConversation(
conversationId: string,
newMessage: string
): Promise<Anthropic.Message | null> {
const checkpoint = this.restoreCheckpoint(conversationId);
if (!checkpoint) {
console.log('Checkpoint expired or not found');
return null;
}
// Resume with cached context
const messages = [
...checkpoint.messages,
{ role: 'user' as const, content: newMessage }
];
return await client.messages.create({
model: 'claude-3-5-sonnet-20241022',
max_tokens: 1024,
messages
});
}
}
Hybrid Caching with External Stores
Combine Claude's prompt caching with external caching layers (Redis, Memcached) for even better performance.
Two-Tier Cache Pattern
import redis
import json
from typing import Optional
class HybridCacheManager:
"""Combine Redis caching with Claude prompt caching."""
def __init__(self, redis_url: str, anthropic_api_key: str):
self.redis_client = redis.from_url(redis_url)
self.anthropic_client = Anthropic(api_key=anthropic_api_key)
def get_cached_response(
self,
cache_key: str,
ttl_seconds: int = 3600
) -> Optional[str]:
"""Check Redis for cached response."""
cached = self.redis_client.get(cache_key)
if cached:
return json.loads(cached)
return None
def set_cached_response(
self,
cache_key: str,
response: str,
ttl_seconds: int = 3600
):
"""Store response in Redis."""
self.redis_client.setex(
cache_key,
ttl_seconds,
json.dumps(response)
)
async def query_with_hybrid_cache(
self,
document: str,
question: str,
system_prompt: str
) -> tuple[str, dict]:
"""Query with two-tier caching."""
# Level 1: Check Redis for exact question match
cache_key = f"qa:{hash(document)}:{hash(question)}"
cached_response = self.get_cached_response(cache_key)
if cached_response:
return cached_response, {"cache_tier": "redis", "cost": 0}
# Level 2: Use Claude with prompt caching
response = self.anthropic_client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
system=[
{
"type": "text",
"text": system_prompt,
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": f"Document:\n\n{document}",
"cache_control": {"type": "ephemeral"}
},
{
"type": "text",
"text": question
}
]
}
]
)
answer = response.content[0].text
# Store in Redis for future exact matches
self.set_cached_response(cache_key, answer)
cache_tier = "claude_prompt" if response.usage.cache_read_input_tokens else "none"
return answer, {
"cache_tier": cache_tier,
"cache_read_tokens": response.usage.cache_read_input_tokens or 0,
"cost": calculate_cost(response.usage)
}
# Usage
hybrid_cache = HybridCacheManager(
redis_url="redis://localhost:6379",
anthropic_api_key="your_key"
)
answer, stats = await hybrid_cache.query_with_hybrid_cache(
document=long_document,
question="What are the key terms?",
system_prompt="You are a legal analyst..."
)
print(f"Answer: {answer}")
print(f"Cache tier: {stats['cache_tier']}")
print(f"Cost: ${stats['cost']:.4f}")
Cost Optimization Algorithms
Automatically determine the optimal caching strategy based on usage patterns.
Adaptive Caching Strategy
interface UsagePattern {
requestsPerHour: number;
averageDocumentTokens: number;
averageQuestionTokens: number;
cacheHitRate: number;
}
class AdaptiveCacheOptimizer {
private usageHistory: UsagePattern[] = [];
recordUsage(pattern: UsagePattern): void {
this.usageHistory.push(pattern);
if (this.usageHistory.length > 100) {
this.usageHistory.shift();
}
}
shouldEnableCaching(): boolean {
if (this.usageHistory.length < 10) return true; // Default to enabled
const recent = this.usageHistory.slice(-10);
const avgRequestsPerHour = recent.reduce((sum, p) => sum + p.requestsPerHour, 0) / recent.length;
const avgCacheHitRate = recent.reduce((sum, p) => sum + p.cacheHitRate, 0) / recent.length;
// Enable caching if:
// 1. More than 5 requests per hour, OR
// 2. Cache hit rate above 50%
return avgRequestsPerHour > 5 || avgCacheHitRate > 0.5;
}
getOptimalCacheBreakpoints(
systemTokens: number,
toolTokens: number,
documentTokens: number
): string[] {
const breakpoints: string[] = [];
// Always cache if above threshold
if (systemTokens > 1000) breakpoints.push('system');
if (toolTokens > 1000) breakpoints.push('tools');
if (documentTokens > 5000) breakpoints.push('document');
// Limit to 4 breakpoints (API limit)
return breakpoints.slice(0, 4);
}
estimateMonthlySavings(
requestsPerMonth: number,
avgCachedTokens: number,
cacheHitRate: number
): number {
const inputCostPer1M = 3.00; // Sonnet pricing
const cacheReadCostPer1M = 0.30;
// Cost without caching
const costWithoutCache = (requestsPerMonth * avgCachedTokens / 1_000_000) * inputCostPer1M;
// Cost with caching (first request writes, rest read)
const cacheWrites = requestsPerMonth * (1 - cacheHitRate);
const cacheReads = requestsPerMonth * cacheHitRate;
const costWithCache =
(cacheWrites * avgCachedTokens / 1_000_000) * inputCostPer1M * 1.25 + // 25% premium for writes
(cacheReads * avgCachedTokens / 1_000_000) * cacheReadCostPer1M;
return costWithoutCache - costWithCache;
}
}
// Usage
const optimizer = new AdaptiveCacheOptimizer();
// Record usage over time
optimizer.recordUsage({
requestsPerHour: 25,
averageDocumentTokens: 15000,
averageQuestionTokens: 100,
cacheHitRate: 0.85
});
if (optimizer.shouldEnableCaching()) {
const breakpoints = optimizer.getOptimalCacheBreakpoints(2000, 1700, 15000);
console.log('Recommended breakpoints:', breakpoints);
const savings = optimizer.estimateMonthlySavings(10000, 15000, 0.85);
console.log(`Estimated monthly savings: $${savings.toFixed(2)}`);
}
Cache Analytics and Monitoring
Track cache performance to optimize your strategy over time.
Cache Metrics Collector
from dataclasses import dataclass
from datetime import datetime
from typing import List
import statistics
@dataclass
class CacheMetrics:
timestamp: datetime
cache_creation_tokens: int
cache_read_tokens: int
input_tokens: int
output_tokens: int
response_time_ms: float
cost: float
class CacheAnalytics:
"""Collect and analyze cache performance metrics."""
def __init__(self):
self.metrics: List[CacheMetrics] = []
def record_request(
self,
usage: dict,
response_time_ms: float,
model: str = "claude-3-5-sonnet-20241022"
):
"""Record metrics from a request."""
# Calculate cost
pricing = {
"input": 3.00,
"cache_write": 3.75,
"cache_read": 0.30,
"output": 15.00
}
cost = (
(usage.get('input_tokens', 0) / 1_000_000 * pricing['input']) +
(usage.get('cache_creation_input_tokens', 0) / 1_000_000 * pricing['cache_write']) +
(usage.get('cache_read_input_tokens', 0) / 1_000_000 * pricing['cache_read']) +
(usage.get('output_tokens', 0) / 1_000_000 * pricing['output'])
)
self.metrics.append(CacheMetrics(
timestamp=datetime.now(),
cache_creation_tokens=usage.get('cache_creation_input_tokens', 0),
cache_read_tokens=usage.get('cache_read_input_tokens', 0),
input_tokens=usage.get('input_tokens', 0),
output_tokens=usage.get('output_tokens', 0),
response_time_ms=response_time_ms,
cost=cost
))
def get_summary(self, last_n: int = 100) -> dict:
"""Get summary statistics."""
recent = self.metrics[-last_n:]
if not recent:
return {}
total_requests = len(recent)
cache_hits = sum(1 for m in recent if m.cache_read_tokens > 0)
cache_hit_rate = cache_hits / total_requests if total_requests > 0 else 0
total_cost = sum(m.cost for m in recent)
avg_response_time = statistics.mean(m.response_time_ms for m in recent)
# Calculate savings
total_cached_tokens = sum(m.cache_read_tokens for m in recent)
savings = total_cached_tokens / 1_000_000 * (3.00 - 0.30) # Difference between input and cache read
return {
"total_requests": total_requests,
"cache_hit_rate": f"{cache_hit_rate * 100:.1f}%",
"total_cost": f"${total_cost:.2f}",
"estimated_savings": f"${savings:.2f}",
"avg_response_time_ms": f"{avg_response_time:.0f}",
"total_cached_tokens": f"{total_cached_tokens:,}",
"efficiency_score": f"{(cache_hit_rate * 100):.0f}/100"
}
def export_to_csv(self, filename: str):
"""Export metrics to CSV for analysis."""
import csv
with open(filename, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow([
'timestamp', 'cache_creation_tokens', 'cache_read_tokens',
'input_tokens', 'output_tokens', 'response_time_ms', 'cost'
])
for m in self.metrics:
writer.writerow([
m.timestamp.isoformat(),
m.cache_creation_tokens,
m.cache_read_tokens,
m.input_tokens,
m.output_tokens,
m.response_time_ms,
m.cost
])
# Usage
analytics = CacheAnalytics()
# Record requests
import time
start = time.time()
response = client.messages.create(...)
elapsed_ms = (time.time() - start) * 1000
analytics.record_request(response.usage, elapsed_ms)
# Get summary
summary = analytics.get_summary(last_n=100)
print(json.dumps(summary, indent=2))
# Export for analysis
analytics.export_to_csv('cache_metrics.csv')
Edge Cases and Failure Modes
Handling Cache Misses Gracefully
class RobustCacheHandler {
async queryWithFallback(
document: string,
question: string,
maxRetries: number = 2
): Promise<Anthropic.Message> {
let attempt = 0;
let lastError: Error | null = null;
while (attempt < maxRetries) {
try {
const response = await client.messages.create({
model: 'claude-3-5-sonnet-20241022',
max_tokens: 1024,
messages: [
{
role: 'user',
content: [
{
type: 'text',
text: `Document:\n\n${document}`,
cache_control: { type: 'ephemeral' }
},
{
type: 'text',
text: question
}
]
}
]
});
// Check if cache was used as expected
if (attempt > 0 && !response.usage.cache_read_input_tokens) {
console.warn('Cache miss on retry - content may have changed');
}
return response;
} catch (error) {
lastError = error as Error;
attempt++;
if (attempt < maxRetries) {
// Exponential backoff
await new Promise(resolve => setTimeout(resolve, Math.pow(2, attempt) * 1000));
}
}
}
throw new Error(`Failed after ${maxRetries} attempts: ${lastError?.message}`);
}
}
Detecting Cache Corruption
class CacheIntegrityChecker:
"""Detect when cache behavior is unexpected."""
def __init__(self):
self.expected_cache_tokens = {}
def validate_cache_usage(
self,
request_id: str,
usage: dict,
expected_cached_tokens: int
) -> bool:
"""Check if cache usage matches expectations."""
cache_read = usage.get('cache_read_input_tokens', 0)
cache_creation = usage.get('cache_creation_input_tokens', 0)
# First request should create cache
if request_id not in self.expected_cache_tokens:
self.expected_cache_tokens[request_id] = expected_cached_tokens
if cache_creation == 0:
print(f"⚠️ Warning: Expected cache creation but got none")
return False
return True
# Subsequent requests should read from cache
if cache_read == 0:
print(f"⚠️ Warning: Expected cache read but got none - cache may have expired")
return False
# Check if cached amount matches expectations
tolerance = 0.1 # 10% tolerance
if abs(cache_read - expected_cached_tokens) / expected_cached_tokens > tolerance:
print(f"⚠️ Warning: Cache read {cache_read} differs from expected {expected_cached_tokens}")
return False
return True
# Usage
checker = CacheIntegrityChecker()
response = client.messages.create(...)
is_valid = checker.validate_cache_usage(
request_id="doc_123",
usage=response.usage,
expected_cached_tokens=15000
)
if not is_valid:
# Take corrective action
invalidate_cache("doc_123")
Production Checklist
Before deploying advanced caching patterns to production:
- [ ] Monitor cache hit rates - Track and alert on unexpected drops
- [ ] Set up cache warming - For predictable high-traffic content
- [ ] Implement fallback logic - Handle cache expiry gracefully
- [ ] Version your content - Detect when invalidation is needed
- [ ] Use hierarchical caching - Minimize invalidation impact
- [ ] Track costs - Measure actual savings vs. projections
- [ ] Set cache TTLs - Refresh before 60-minute expiry
- [ ] Test edge cases - Cache misses, expiry, corruption
- [ ] Document your strategy - Make it maintainable for your team
- [ ] A/B test configurations - Find optimal breakpoint placement
Conclusion
Advanced prompt caching patterns can dramatically improve both performance and cost-efficiency of your Claude applications. The key is to:
- Understand your usage patterns - Not all applications benefit equally
- Layer your caches strategically - Minimize invalidation impact
- Monitor and adapt - Use analytics to optimize over time
- Handle failures gracefully - Cache expiry is inevitable
- Combine with external caching - Redis + prompt caching = maximum efficiency
Start with basic caching, measure the results, then gradually adopt these advanced patterns where they provide the most value.
Next steps:
- Implement cache analytics in your application
- Experiment with hierarchical caching for your use case
- Set up automated cache warming for high-traffic content
- Monitor and optimize based on real usage data